 synchronized关键字使用指南
synchronized关键字使用指南
# 写在文章开头
在 Java 多线程环境中,synchronized 关键字是一种常用的同步机制,用于确保多个线程对共享资源的互斥访问。合理使用 synchronized 可以有效避免数据竞争和不一致问题,但不当使用也可能导致性能瓶颈或死锁。本文将探讨 synchronized 在多线程环境下的使用技巧和注意事项,帮助开发者更好地理解和应用这一机制。
我是 SharkChili ,欢迎关注我的公众号:写代码的SharkChili,也欢迎您了解我的开源项目 mini-redis:https://github.com/shark-ctrl/mini-redis (opens new window)。
为方便与读者交流,现已创建读者群。关注下方公众号获取我的联系方式,添加时备注加群即可加入。
# 详解synchronized使用注意事项
# 注意多共享资源操作的原子性
看下面这段代码,有两个volatile变量a、b,然后有两个线程操作这两个变量,一个变量对a、b进行自增,另一个线程发现a<b的时候就打印a>b的结果:
private volatile int a = 1;
private volatile int b = 1;
public void add() {
log.info("add start");
//循环累加
for (int i = 0; i < 100_0000; i++) {
a++;
b++;
}
log.info("add done");
}
public void compare() {
log.info("compare start");
for (int i = 0; i < 100_0000; i++) {
//如果a<b,则打印a>b的结果
if (a < b) {
log.info("a:{},b:{},a>b:{} ", a, b, a > b);
}
}
log.info("compare done");
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
随后我们给出两个线程分别调用add和compare方法:
public static void main(String[] args) throws InterruptedException {
CountDownLatch countDownLatch = new CountDownLatch(2);
Main interesting = new Main();
//线程1
new Thread(() -> {
interesting.add();
countDownLatch.countDown();
},"t1").start();
//线程2
new Thread(() -> {
interesting.compare();
countDownLatch.countDown();
},"t2").start();
countDownLatch.await();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
结果出现了很奇怪的现象,我们发现进行了某些线程得到了进入了a<b的if分支,偶发的输出a>b结果却为true:
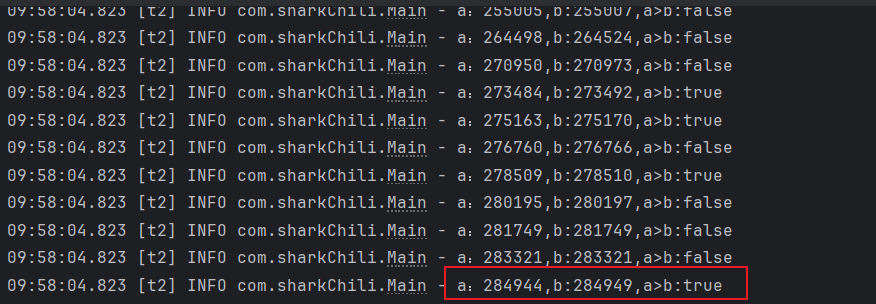
尽管我们使用volatile保证了两个变量的可见性,确保一个线程变量对于另一个线程是可见的。但我们没有保证临界资源的互斥,即线程2判断到a<b的时候,线程1依然可以操作变量a和b这就会导致下面这种情况:
- 线程1的
add方法发生因为两个变量自增操作没有关联系,按照CPU流水线的设计理念(亦或者JVM解释的指令乱序生成机器码),导致CPU未能严格在那好代码顺序执行,b先进行自增。 - 线程2在线程1的某个执行点得到a<b。
- 线程1进入逻辑后尝试读取a和b的结果,由于处理器或者
JIT等原因,此时自增的指令发生重排序,导致自增顺序被打乱。 - 线程2打印a大于b的结果变为
true。
很明显导致问题的原因就是两个线程进行并发操作时没有保证单位时间内只有一个线程操作临界资源,结合as-if-serial规则在单线程的情况下,指令重排序只能对不影响处理结果的部分进行重排序,这就导致并发操作其间a、b结果大小可能是瞬息万变的。
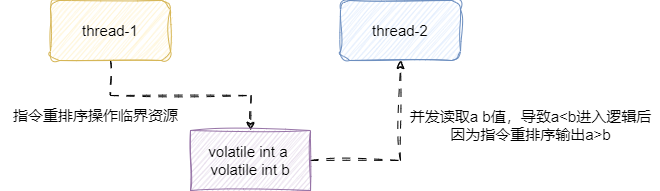
所以我们都在实例方法上添加一个synchronized 关键字,确保每一次操作都能锁住实例对象,避免另一个线程操作:
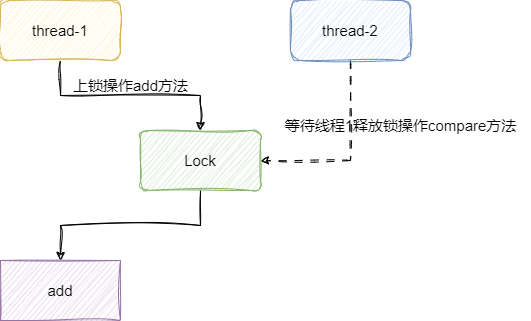
对应我们给出修改后的代码,因为操作临界资源时上了锁,单位时间内只有一个线程可以操作临界资源,对应的问题就有了很好的解决:
public synchronized void add() {
log.info("add start");
for (int i = 0; i < 100_0000; i++) {
b++;
a++;
}
log.info("add done");
}
public synchronized void compare() {
log.info("compare start");
for (int i = 0; i < 100_0000; i++) {
//如果a<b,则打印a>b的结果
if (a < b) {
log.info("a:{},b:{},a>b:{} ", a, b, a > b);
}
}
log.info("compare done");
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 确保临界资源和锁处于一个维度
我们现在有这么一个Data 对象,它包含一个静态变量counter。还有一个重置变量值的方法reset。
@Slf4j
public class Data {
@Getter
@Setter
private static int counter = 0;
public static int reset() {
counter = 0;
return counter;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
这个变量需要被多线程操作,于是我们给它添加了一个add方法:
public synchronized void wrongAdd() {
counter++;
}
2
3
4
5
测试代码如下,你们猜猜最终的结果是多少呢?
public static void main(String[] args) {
Data.reset();
IntStream.rangeClosed(1, 100_0000)
.parallel()
.forEach(i -> {
new Data().wrongAdd();
});
log.info("counter:{}", Data.getCounter());
}
2
3
4
5
6
7
8
9
10
11
输出结果如下,感兴趣的读者可以试试看,这个值几乎每一次都不一样。原因是什么呢?
2023-03-19 14:42:53,006 INFO Data:54 - counter:390472
2
仔细看看我们的add方法,它在实例上方法上锁,锁的对象是当前对象,在看看我们的代码并行流中的每一个线程的写法,永远都是new一个data对象执行add方法,大家各自用各自的锁,很可能出现两个线程同时读取到一个值0,然后一起自增1,导致最终结果变为1而不是2:
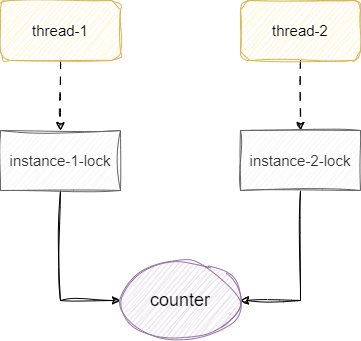
如果可以改变调用方式,那么我们就让所有线程使用同一个实例对象,保证上的锁都是基于同一个实例的对象锁:
public static void main(String[] args) {
Data.reset();
//创建一个data对象,让所有线程都通过data对象的锁进行操作
Data data = new Data();
IntStream.rangeClosed(1, 100_0000)
.parallel()
.forEach(i -> {
data.wrongAdd();
});
log.info("counter:{}", Data.getCounter());
}
2
3
4
5
6
7
8
9
10
11
12
输出结果
2023-03-19 14:44:26,972 INFO Data:55 - counter:1000000
如果不能改变调用方式,我们就修改调用方法,让所有对象实例都用同一把锁。
private static Object locker = new Object();
public void rightAdd() {
synchronized (locker) {
counter++;
}
}
2
3
4
5
6
7
8
9
10
最后将并发累加改为调用data.rightAdd();,可以看到输出结果也是正确的:
2023-03-19 14:55:21,095 INFO Data:56 - counter:1000000
2
# 避免锁的粒度过粗
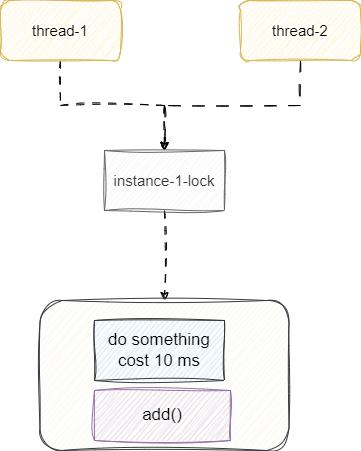
有时候我们锁使用的确实没有错,但是锁的粒度太粗了,将一些非常耗时的方法放到锁里面,导致性能问题,就像下面这段代码。我们用slow模拟耗时的方法,将slow放到锁里面,这意味每个线程得到锁就必须等待上一个线程完成这个10毫秒的方法加需要上锁的业务逻辑才行。
private static List<Object> list = new ArrayList<>();
public void slow() {
try {
TimeUnit.MILLISECONDS.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public void add() {
synchronized (Test.class) {
slow();
list.add(1);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
我们的压测代码如下
StopWatch stopWatch = new StopWatch();
stopWatch.start("add ");
IntStream.rangeClosed(1, 1000).parallel()
.forEach(i -> {
new Test().add();
});
stopWatch.stop();
Assert.isTrue(list.size() == 1000, "size error");
log.info(stopWatch.prettyPrint());
2
3
4
5
6
7
8
9
10
输出结果如下,可以看到1000个并行流就使用了15s左右:
-----------------------------------------
ms % Task name
-----------------------------------------
15878 084% add
2
3
4
所以我们需要对这个代码进行一次改造,将耗时的操作放到锁外面,让耗时操作放在临界资源之外,保证CPU感知到线程休眠,可以及时切换执行其他线程休眠逻辑,尽可能利用CPU让尽可能多的线程进入IO状态然后进入锁内部操作:
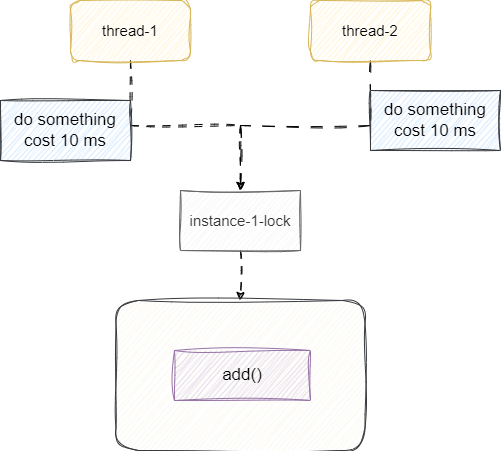
public void add2() {
slow();
synchronized (Test.class) {
list.add(1);
}
}
2
3
4
5
6
我们再来完整压测一次:
@org.junit.Test
public void test() {
StopWatch stopWatch = new StopWatch();
stopWatch.start("add ");
IntStream.rangeClosed(1, 1000).parallel()
.forEach(i -> {
new Test().add();
});
stopWatch.stop();
Assert.isTrue(list.size() == 1000, "size error");
list.clear();
stopWatch.start("add2 ");
IntStream.rangeClosed(1, 1000).parallel()
.forEach(i -> {
new Test().add2();
});
stopWatch.stop();
Assert.isTrue(list.size() == 1000, "size error");
log.info(stopWatch.prettyPrint());
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
可以看到改造后的性能远远高于前者
2023-03-19 15:10:47,888 INFO Test:69 - StopWatch '': running time (millis) = 18853
-----------------------------------------
ms % Task name
-----------------------------------------
15878 084% add
02975 016% add2
2
3
4
5
6
# 注意死锁问题
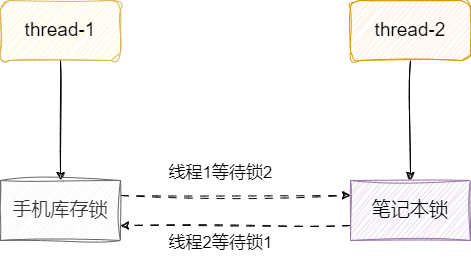
有时候锁使用不当可能会导致线程死锁,其中造成死锁最经典的原因就是环路等待。
如下图,线程1获取锁1之后还要获取锁2,才能操作临界资源,这意味着线程1必须同时拿到两把锁完成手头工作后才能释放锁。 同理线程2先获取锁2再去获取锁1,才能操作临界资源,同样必须操作完临界资源后才能释放锁。双方就这样拿着对方需要的东西互相阻塞僵持着,造成死锁。
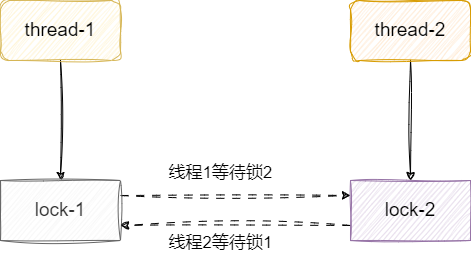
我们现在有这样一个需求,不同用户需要购买不同的商品,用户执行库存扣减的时候必须拿到所有需要购买的商品的锁才成完成库存扣减。
例如用户1想购买笔者本和手机,它就必须同时拿到手机和笔者本两个商品的锁才能操作资源。这种做法可能会导致上述所说的死锁问题,有个用户打算先买笔者本再买手机,另一个用户打算先买手机再买笔者本,这使得他们获取锁的顺序是相反的,如果他们同时执行业务逻辑。双方先取的各自的第一把锁,准备尝试获取第二把锁的时候发现锁被对方持有,双方僵持不下,造成线程死锁。
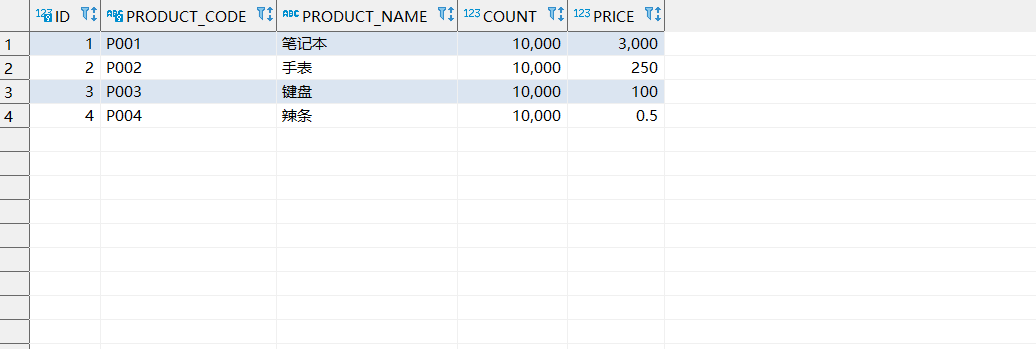
我们不妨来演示一下这个问题,首先我们先来看看商品表,可以看到P001为笔记本,P002为手表:
SELECT * FROM product p ;
2
为了保证所有的商品的锁只有一把,我们会使用一个静态变量来存储所有商品的锁。所以我们现在controller上定义一个静态变量productDTOMap ,key为商品的code,value为商品对象,这个商品对象中就包含扣减库存时需要用到的锁。
private static Map<String, ProductDTO> productDTOMap = new HashMap<>();
然后我们的controller就用InitializingBean 这个扩展点完成商品锁的加载。
@RestController
@RequestMapping()
public class ProductController implements InitializingBean {
@Override
public void afterPropertiesSet() throws Exception {
//获取商品
List<Product> productList = productService.list();
//将商品转为map,用code作为key,ProductDTO 作为value,并为其设置锁ReentrantLock
productDTOMap = productList.stream()
.collect(Collectors.toMap(p -> p.getProductCode(), p -> {
ProductDTO dto = new ProductDTO();
dto.setLock(new ReentrantLock());
return dto;
}));
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
接下来就能编写我们的库存扣减的逻辑了,步骤很简单:
- 根据用户传入的code找到对应的商品对象。
- 获取要购买的商品的锁。
- 所有锁都拿到完成商品扣减,有一把锁没拿到则将所有的锁都释放并返回false告知用户本地下单失败。
@PostMapping("/product/deductCount")
ResultData<Boolean> deductCount(@RequestBody List<String> codeList) {
//获取商品
QueryWrapper<Product> query = new QueryWrapper<>();
query.in("PRODUCT_CODE", codeList);
//存储用户获得的锁
List<ReentrantLock> lockList = new ArrayList<>();
//遍历每个商品对象,并尝试获得这些商品的锁
for (String code : codeList) {
if (productDTOMap.containsKey(code)) {
try {
ReentrantLock lock = productDTOMap.get(code).getLock();
//如果得到这把锁就将锁存到list中
if (lock.tryLock(60, TimeUnit.SECONDS)) {
lockList.add(lock);
} else {
//只要有一把锁没有得到,就直接将list中所有的锁释放并返回false,告知用户下单失败
lockList.forEach(l -> l.unlock());
return ResultData.success(false);
}
} catch (InterruptedException e) {
logger.error("上锁失败,请求参数:{},失败原因:{}", JSON.toJSONString(codeList), e.getMessage(), e);
return ResultData.success(false);
}
}
}
//到这里说明得到了所有的锁,直接执行商品扣减的逻辑了
try {
codeList.forEach(code -> {
productService.deduct(code, 1);
});
} finally {
//释放所有的锁
lockList.forEach(l -> l.unlock());
}
//返回结果
return ResultData.success(true);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
完成后我们即可通过下面这个地址进行请求:
http://localhost:9002/product/deductCount
对应的我们的请求可以基于下面这个参数顺序调换进行请求,为方便复现死锁问题读者可以通过多线程调试模式将实现两个线程先拿各自的一把锁,然后尝试获取对方锁的情况:
# 线程1参数
[
"P001",
"P002"
]
# 线程2参数
[
"P002",
"P001"
]
2
3
4
5
6
7
8
9
10
11
12
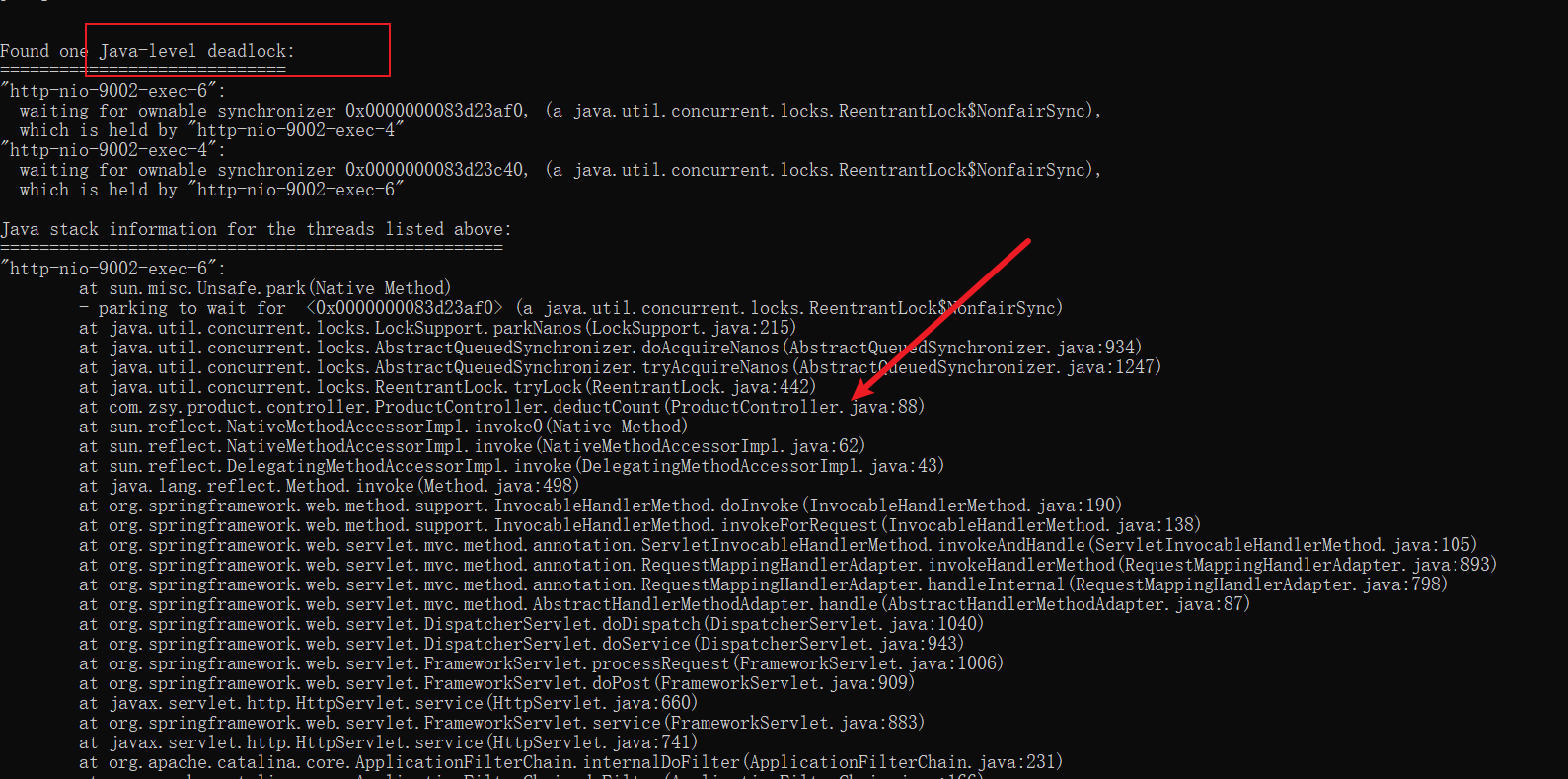
发现请求阻塞之后,通过jstack 查看应用使用情况。
jstack -l 6792
从控制台可以看到,正是环路等待的取锁顺序,导致我们tryLock的方法上出现了死锁的情况。
解决方式也很简单,既然造成死锁的原因是双方取锁顺序相反,那么我们为什么不让两个线程按照相同的顺序取锁呢?
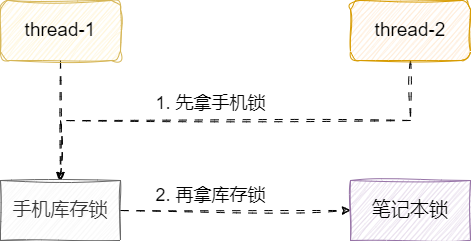
我们将双方购买的商品顺序,按照code排序一下,让两个线程都按照同一个方向的顺序取锁,不就可以避免死锁问题了?代码改动的地方很少,只需添加这样一行让用户商品code排下序,这样后续的取锁逻辑就保持一致了。
Collections.sort(codeList);
# 小结
锁虽然可以解决线程安全问题,但是使用时必须注意以下几点:
- 注意保证锁的原子性。
- 注意锁的层级,实例对象之间竞争就必须同一个对象作为锁而不是各自的实例对象。
- 注意锁的粒度不能过大,避免将不会造成线程安全且耗时的方法放到锁中。
- 注意环路死锁问题。
我是 SharkChili ,欢迎关注我的公众号:写代码的SharkChili,也欢迎您了解我的开源项目 mini-redis:https://github.com/shark-ctrl/mini-redis (opens new window)。
为方便与读者交流,现已创建读者群。关注下方公众号获取我的联系方式,添加时备注加群即可加入。
# 参考
Java 业务开发常见错误 100 例:https://time.geekbang.org/column/intro/294?utm_term=zeus134KG&utm_source=blog&utm_medium=zhuye (opens new window)
